Привет, Хабр! Представляю вашему вниманию перевод статьи «Demystifying memory management in modern programming languages» за авторством Deepu K Sasidharan.
В данной серии статей мне бы хотелось развеять завесу мистики над управлением памятью в программном обеспечении (далее по тексту — ПО) и подробно рассмотреть возможности, предоставляемые современными языками программирования. Надеюсь, что мои статьи помогут читателю заглянуть под капот этих языков и узнать для себя нечто новое.
Углублённое изучение концептов управления памятью позволяет писать более эффективное ПО, потому как стиль и практики кодирования оказывают большое влияние на принципы выделения памяти для нужд программы.
Часть 1: Введение в управление памятью
Управление памятью — это целый набор механизмов, которые позволяют контролировать доступ программы к оперативной памяти компьютера. Данная тема является очень важной при разработке ПО и, при этом, вызывает затруднения или же вовсе остаётся черным ящиком для многих программистов.
Когда программа выполняется в операционный системе компьютера, она нуждается в доступе к оперативной памяти (RAM) для того, чтобы:
- загружать свой собственный байт-код для выполнения;
- хранить значения переменных и структуры данных, которые используются в процессе работы;
- загружать внешние модули, которые необходимы программе для выполнения задач.
Устройство памяти в программировании
Переходим к анализу ключевых концепций программирования, связанных с управлением памятью. Сначала обсудим стек и кучу — два фундаментальных механизма, лежащих в основе управления памятью. Затем рассмотрим их взаимодействие и особенности работы в процессе выполнения функций и методов.
Стек и куча представляют собой области памяти, используемые программами для хранения данных во время выполнения, но они используются по-разному и для разных целей.
Стек (Stack)
Стек — это область памяти, где функции хранят свои переменные и информацию для выполнения. Представьте стек как физическую стопку подносов в ресторане: вы можете добавить поднос сверху (push) или взять верхний поднос (pop). Аналогично, когда функция вызывается, ее локальные переменные и информация о вызове кладутся на стек сверху, и забираются сверху (уничтожаются), когда функция завершает работу.
Стек обеспечивает быстрый доступ к данным и автоматическое управление памятью, но имеет ограниченный размер. Если ваша программа использует больше стековой памяти, чем доступно, программа может завершиться с ошибкой переполнения стека.
Куча (Heap)
Куча — это область памяти, где данные могут быть размещены динамически во время выполнения программы. В отличие от стека, где данные удаляются автоматически после выхода из функции, данные в куче остаются, пока их явно не удалить.
C# Стек и Куча | Stack and Heap | Часть 1
Это делает кучу идеальным местом для хранения данных, которые должны пережить вызов функции, или для работы с большими объемами данных. Однако работа с кучей требует аккуратного управления: если вы не удаляете объекты, когда они больше не нужны, может произойти утечка памяти, что в конечном итоге может привести к исчерпанию доступной памяти.
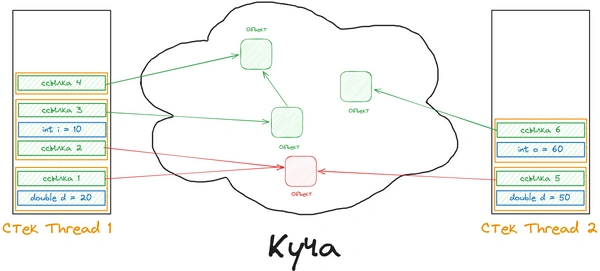
Для удобства визуализируем стек и кучу. Серые объекты потеряли свою ссылку из стека, их необходимо удалить, чтобы освободить память для новых объектов.

Объект может содержать методы, и эти методы могут содержать локальные переменные. Эти локальные переменные также хранятся в стеке потоков, даже если объект, которому принадлежит метод, хранится в куче.
Стек
Когда функция вызывается, для нее выделяется блок памяти на вершине стека. Этот блок памяти, известный как «фрейм стека», содержит пространство для всех локальных переменных функции, а также информацию, такую как возвращаемый адрес: адрес в коде, к которому следует вернуться после завершения функции.
Когда функция вызывает другую функцию, для новой функции выделяется свой фрейм стека, и она становится текущей активной функцией. Когда функция завершает свою работу, ее фрейм стека удаляется, и управление возвращается обратно в вызывающую функцию.
Синхронизация в Java служит для контроля доступа нескольких потоков к общим ресурсам. Синхронизация может быть реализована с использованием ключевого слова synchronized или специальных классов, таких как ReentrantLock или Semaphore .
Сборщик мусора в Java работает в многопоточной среде и способен обрабатывать объекты из всех потоков. Однако следует быть внимательным с долгоживущими объектами и ресурсами, которые могут заблокировать сборщик мусора.
Ключевые различия между стеком и кучей

| Тип структур данных | Стек — это линейная структура данных. | Куча — это иерархическая структура данных. |
| Скорость доступа | Скоростной доступ | Медленнее по сравнению со стеком |
| Управление пространством | Операционная система эффективно управляет пространством, поэтому память никогда не будет фрагментирована. | Пространство кучи используется не так эффективно. Память может стать фрагментированной, поскольку блоки памяти сначала выделяются, а затем освобождаются. |
| О компании | Только локальные переменные | Это позволяет вам получить глобальный доступ к переменным. |
| Ограничение размера пространства | Ограничение на размер стека зависит от ОС. | Не имеет конкретного ограничения на размер памяти. |
| Изменение размера | Размер переменных нельзя изменить | Размер переменных можно изменить. |
| Выделение памяти | Память выделяется в непрерывном блоке. | Память выделяется в любом случайном порядке. |
| Распределение и освобождение | Автоматически выполняется инструкциями компилятора. | Это делается вручную программистом. |
| Распределение | Не требует освобождения переменных. | Необходимо явное освобождение от распределения. |
| Цена | Меньше | Больше |
| Реализация | Стек может быть реализован тремя способами: на основе простого массива, с использованием динамической памяти и на основе связанного списка. | Куча может быть реализована с использованием массива и деревьев. |
| Главная проблема | Нехватка памяти | Фрагментация памяти |
| Местонахождение ссылки | Автоматические инструкции времени компиляции. | Адекватный |
| Трансформируемость | Исправленный размер | Изменение размера возможно |
| Время доступа | Быстрее | Помедленнее |
Преимущества использования стека

Вот плюсы/преимущества использования стека:
- Помогает вам управлять данными с помощью метода «Последним поступило — первым отправлено» (LIFO), что невозможно при использовании связанного списка и массива.
- Когда функция вызывается, локальные переменные сохраняются в стеке и автоматически уничтожаются после возврата.
- Стек используется, когда переменная не используется вне этой функции.
- Это позволяет вам контролировать выделение и освобождение памяти.
- Стек автоматически очищает объект.
- Не легко испортить
- Размер переменных не может быть изменен.
Стек
Стек — это область оперативной памяти, которая создаётся для каждого потока. Он работает в порядке LIFO (Last In, First Out), то есть последний добавленный в стек кусок памяти будет первым в очереди на вывод из стека. Каждый раз, когда функция объявляет новую переменную, она добавляется в стек, а когда эта переменная пропадает из области видимости (например, когда функция заканчивается), она автоматически удаляется из стека. Когда стековая переменная освобождается, эта область памяти становится доступной для других стековых переменных.
Синтаксический сахар. Опаснее, чем кажется?
Из-за такой природы стека управление памятью оказывается весьма логичным и простым для выполнения на ЦП; это приводит к высокой скорости, в особенности потому, что время цикла обновления байта стека очень мало, т.е. этот байт скорее всего привязан к кэшу процессора. Тем не менее, у такой строгой формы управления есть и недостатки. Размер стека — это фиксированная величина, и превышение лимита выделенной на стеке памяти приведёт к переполнению стека. Размер задаётся при создании потока, и у каждой переменной есть максимальный размер, зависящий от типа данных. Это позволяет ограничивать размер некоторых переменных (например, целочисленных), и вынуждает заранее объявлять размер более сложных типов данных (например, массивов), поскольку стек не позволит им изменить его. Кроме того, переменные, расположенные на стеке, всегда являются локальными.
В итоге стек позволяет управлять памятью наиболее эффективным образом — но если вам нужно использовать динамические структуры данных или глобальные переменные, то стоит обратить внимание на кучу.
Куча
Куча — это хранилище памяти, также расположенное в ОЗУ, которое допускает динамическое выделение памяти и не работает по принципу стека: это просто склад для ваших переменных. Когда вы выделяете в куче участок памяти для хранения переменной, к ней можно обратиться не только в потоке, но и во всем приложении. Именно так определяются глобальные переменные. По завершении приложения все выделенные участки памяти освобождаются. Размер кучи задаётся при запуске приложения, но, в отличие от стека, он ограничен лишь физически, и это позволяет создавать динамические переменные.
Вы взаимодействуете с кучей посредством ссылок, обычно называемых указателями — это переменные, чьи значения являются адресами других переменных. Создавая указатель, вы указываете на местоположение памяти в куче, что задаёт начальное значение переменной и говорит программе, где получить доступ к этому значению. Из-за динамической природы кучи ЦП не принимает участия в контроле над ней; в языках без сборщика мусора (C, C++) разработчику нужно вручную освобождать участки памяти, которые больше не нужны. Если этого не делать, могут возникнуть утечки и фрагментация памяти, что существенно замедлит работу кучи.
Разработка на C++ с нуля в 2022 году: дорожная карта
В сравнении со стеком, куча работает медленнее, поскольку переменные разбросаны по памяти, а не сидят на верхушке стека. Некорректное управление памятью в куче приводит к замедлению её работы; тем не менее, это не уменьшает её важности — если вам нужно работать с динамическими или глобальными переменными, пользуйтесь кучей.
Stack and heap. Структуры данных в .NET

![]()
![]()
10.09.2018
![]()
![]()
11728
Рейтинг: 5 . Проголосовало: 2
Вы проголосовали:
Для голосования нужно авторизироваться


В этой статье мы рассмотрим организацию работы с памятью в .NET. Здесь мы узнаем, что такое стек и куча, и для хранения каких типов данных они применяются.
Разделение памяти
По умолчанию, как только .NET приложение запускается и определяется виртуальный адрес текущего процесса, создаются следующие «кучи»:
Куча для кода — JIT-компилируемый нативный код
Малая объектная куча — объекты до 85 кб
Большая объектная куча — объекты свыше 85 кб*
Куча для обработки данных
*примечание: в случае массивов для данных типа double существует исключение, согласно которому они хранятся в большой объектной куче задолго до достижения размера в 85 кб (double[] считается системой «большим» объектом при достижении размера в 1000 элементов). По отношению к оптимизации 32-битного кода это, конечно, не очень хорошо.
Разбиение на большие и малые кучи достаточно целесообразно для улучшения производительности, но об этом позже, когда будем говорить о сборщике мусора.
Элементы, размещенные в кучи, обладают своими адресами, которые являются чем-то вроде указателей на ячейки памяти, где хранятся значения этих элементов.
Впрочем, куча — это не единственная структура данных, которой может похвалиться вселенная .NET. К примеру, есть еще и стек, который крайне полезен для хранения «специфических» типов данных. Сейчас мы рассмотрим в деталях, как устроены эти структуры данных в деталях.
Стек
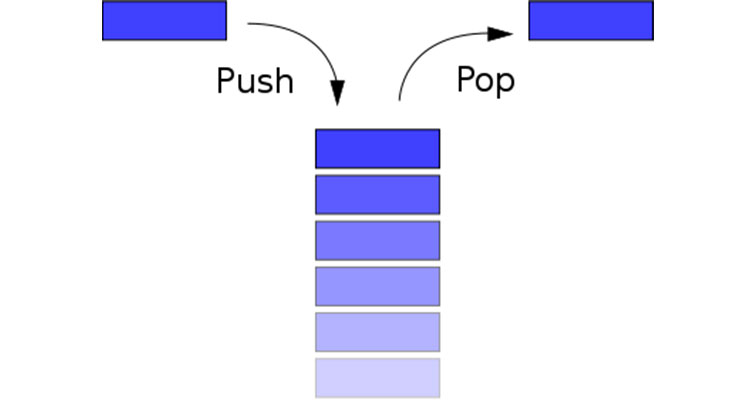
Стек — это структура данных, организованная по принципу LIFO (последний вошел — первый вышел). Если вдуматься, это идеальное решение для хранения данных, к которым вскоре предстоит обратиться (легко извлекаются с вершины стека). Де-факто природа области стека заключается в двух постулатах: «помнить» порядок выполнения и хранить значимые типы данных.
Тема связана со специальностями:
Запоминание порядка выполнения — обращение к стеку
Большая часть кода, который мы пишем, инкапсулирован в классы и методы, которые вызывают другие методы, и так далее. .NET Framework обязан всегда «помнить» порядок вызовов участков кода. Более того, так же нужно хранить данные о состоянии переменных и значениях параметров, передаваемых при вызове методов (дабы суметь восстановить состояние вызывающего метода после завершения работы вызываемого).
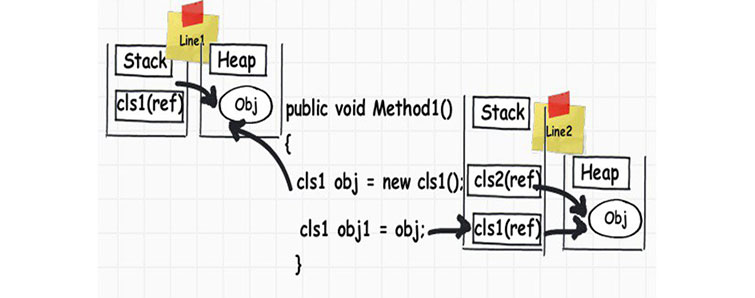
При каждом вызове метода .NET инициализирует стек-фрейм (что-то вроде контейнера), где и хранится вся необходимая информация для выполнения методов: параметры, локальные переменные, адреса вызываемых строчек кода. Стек-фреймы создаются в стеке друг на друге. Все это прекрасно проиллюстрировано ниже:
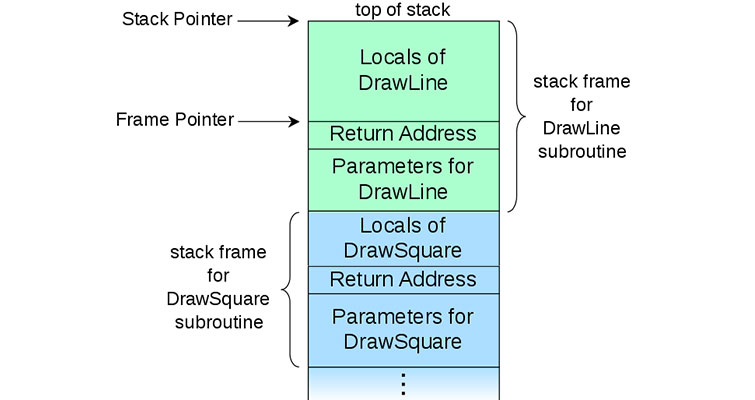
Стек используется для хранения порядка выполнения кода и часто называется стеком вызова, стеком выполнения или программным стеком.
Давайте взглянем на следующий участок кода:
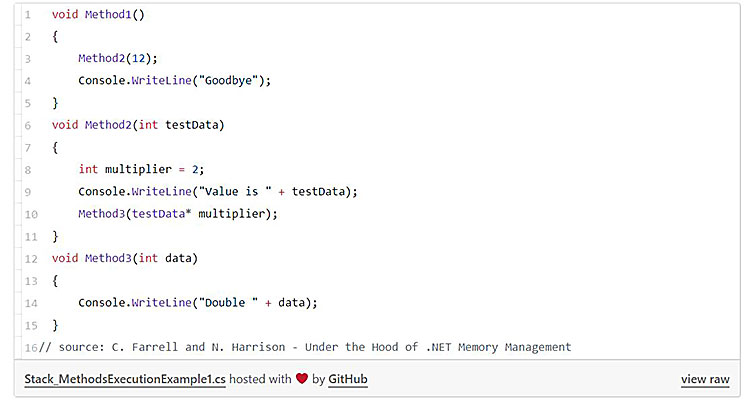
Дабы вызвать Method2, фреймворк должен сохранить адрес конца выполнения метода, которым будет следующая строчка кода (строчка 4 в примере ниже). Этот адрес вместе с параметрами и локальными переменными вызываемого и вызывающего метода хранятся в стеке вызова, как показано на схеме ниже.
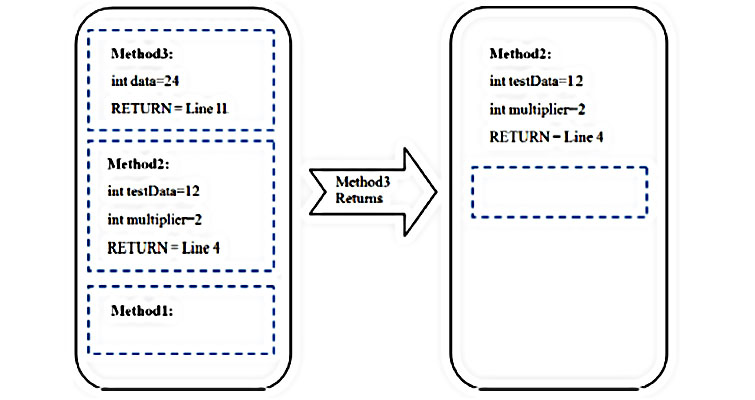
Также вы можете увидеть, что происходит, когда Method3 завершает свое выполнение (стек-фрейм покидает стек вызова).
Хранение значимых типов
Также стек используется для хранения переменных любых значимых типов .NET — включая: bool, decimal, int и так далее.
Ссылочные типы — это типы, которые хранят данные и ссылку на эти данные в рамках одной области памяти. Что так же интересно, так это то, что все локальные переменные значимых типов при завершении выполнения метода очищаются. Это происходит по той причине, что при завершении работы метода его стек-фрейм становится недоступным — стек имеет указатель на начало стек-фрейма на вершине стека вызова (текущий указатель стек-фрейма), который просто перемещается на следующий стек-фрейм после окончания работы текущего (физически данные все еще находятся в стеке вызова, но на практике получить доступ к ним через стандартный .NET-механизм невозможно).
Видео курсы по схожей тематике:

Практикум курса C# Стартовый на примерах из GTA 5

How to C# Стартовый

C# Универсальные шаблоны
Куча
Куча схож со стеком, но если стек представляется в виде последовательности коробок, складируемых друг на друге, в случае с кучей эти самые коробки аккуратно разложены и мы можем получить к ним доступ в любое время.
Хранение ссылочных типов
Все прочие переменные, которые не являются значимыми (производные от object), являются ссылочными типами данных. Все ссылочные типы данных хранятся в управляемой куче (малой или большой — в зависимости от размера). Впрочем, пусть даже и значение объекта хранится в куче, ссылка на него хранится в стеке.
Рассмотрим следующий код:
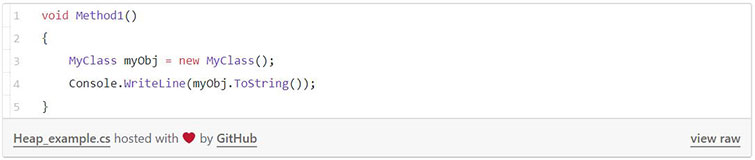
Фигура ниже иллюстрирует, как выглядит стек и куча в плане хранения данных:
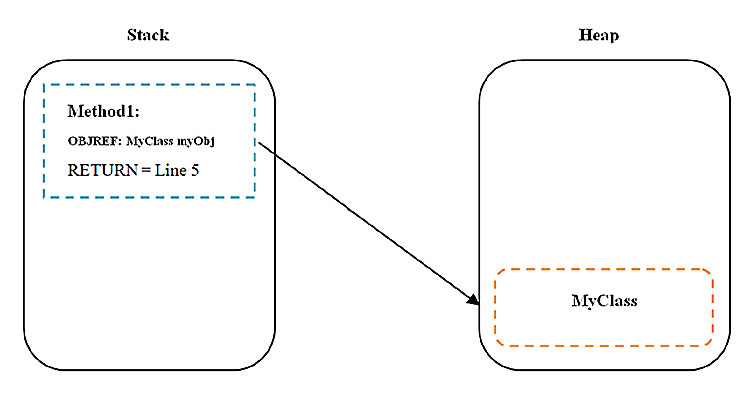
OBJREF, хранимый в стеке, на самом деле является ссылкой на объект MyClass, хранимый в куче.
Заметка: выражение MyClass myObj совершенно не занимает места в куче переменной myObj. Здесь всего лишь создается переменная OBJREF в стеке, после чего она инициализируется значением null. Как только выполняется команда new, куча получает действительное место памяти объекта, а сам ссылочный объект получает по адресу свое значение.
Значимые типы против ссылочных типов (стек против кучи)
Основное различие между ссылочными и значимыми типами данных заключается в том, что ссылочные типы данных передаются по адресу – то есть при передаче ссылочной переменной в виде параметра метода передается всего лишь общий адрес на ячейку памяти с данными объекта. В случае же со значимыми типами данных, между методами передается копия самого объекта. Вот как это выглядит схематически:
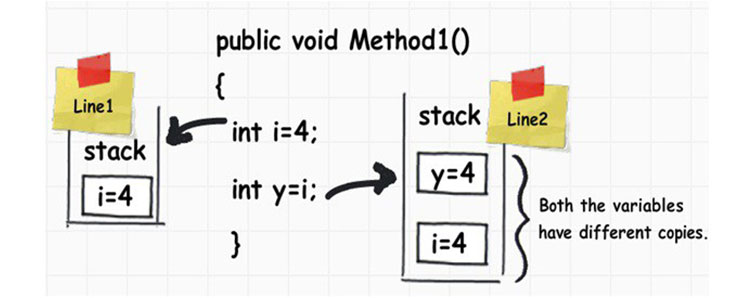
Как уже и было сказано, в случае со ссылочными типами данных, при присваивании ссылочному типу данных значения другого ссылочного типа данных, происходит присваивания адреса, тогда как ячейка памяти со значением остается прежней.
Бесплатные вебинары по схожей тематике:

Каковы реальные шансы найти работу C#/.NET разработчику в 2024 году?

Создание API на PHP и JavaScript для трансляции игры Lines в браузере — видеокурсы ITVDN

Стоит ли учить C# в 2023?
Конечно, хранение одного вида информации в стеке, другого в куче, имеет свои причины, которые мы рассмотрим в грядущих статьях. 🙂
Заключение
В сегодняшней статье мы рассмотрели область стека и кучи, два вида организации памяти для работы в рамках .NET-приложения. В следующей статье мы познакомимся с процессом упаковки и распаковки, а также узнаем, как это сказывается на производительности нашего приложения.
До новых встреч!
Автор перевода: Евгений Лукашук
Как организуется стек?
Когда программисты организуют или реализуют стек, они применяют два варианта: 1. Используя массив и переменную, указывающую на ячейку вершины стека. 2. Используя связанные списки.
У этих двух вариантов реализации стека есть и плюсы, и минусы. К примеру, связанные списки считаются более безопасными в плане применения, ведь каждый добавляемый элемент располагается в динамически созданной структуре (раз нет проблем с числом элементов, значит, отсутствуют дырки в безопасности, позволяющие свободно перемещаться в памяти программного приложения). Однако с точки зрения хранения и скорости применения связанные списки не столь эффективны, так как, во-первых, требуют дополнительного места для хранения указателей, во-вторых, разбросаны в памяти и не расположены друг за другом, если сравнивать с массивами.
Подытожим: стек позволяет управлять памятью более эффективно. Однако помните, что если вам потребуется использовать глобальные переменные либо динамические структуры данных, то лучше обратить своё внимание на кучу.
Стек и куча
Куча — хранилище памяти, расположенное в ОЗУ. Оно допускает динамическое выделение памяти и работает не так, как стек. По сути, речь идёт о простом складе для ваших переменных. Когда вы выделяете здесь участок памяти для хранения, к ней можно обращаться как в потоке, так и во всём приложении в целом (именно так и определяются переменные глобального типа). По завершении работы приложения все выделенные участки освобождаются.
Размер кучи задаётся во время запуска приложения, однако, в отличие от того, как работает стек, в куче размер ограничен только физически, что позволяет создавать переменные динамического типа.
Если сравнивать, опять же, с тем, как работает стек, то куча функционирует медленнее, т. к. переменные разбросаны по памяти, а не находятся вверху стека. Тем не менее данный факт не уменьшает важности кучи, и если вам надо работать с глобальными либо динамическими переменными, она больше подходит. Однако управлять памятью тогда должен программист либо сборщик мусора.
Итак, теперь вы знаете и что такое стек, и что такое куча. Это довольно простые знания, больше подходящие для новичков. Если же вас интересуют более серьёзные профессиональные навыки, выбирайте нужный вам курс по программированию в OTUS!
Очередь
Очередь (queue) — это структура данных, которая напоминает обычную очередь. То есть, в отличие от стека, она работает по принципу «первым пришел — первым ушел» (first in first out, FIFO).

Для очереди определены две операции: добавление элемента в конец очереди (enqueue) и изъятие элемента с начала очереди (dequeue).

В примере объявлена очередь, которая, по сути, представляет собой массив строк:
typedef struct < int head; char * strings [CAPACITY] int size; >queue;
Чтобы реализовать операцию enqueue, необходимо убедиться, что очередь, не переполнена, добавить элемент в конец очереди и увеличить текущий размер на единицу.

Чтобы реализовать операцию dequeue, надо убедиться, что очередь не пуста, увеличить head на единицу, уменьшить текущий размер и вернуть первый элемент очереди.

Куча и переполнение буфера
Куча (heap) — область памяти, которую контролируют непосредственно программисты. Над которой вы, как программисты, получаете непосредственный контроль. Память здесь выделяется в результате вызова функции malloc.
Более глубокие знания о стеке и куче вам пока не понадобятся. Вы их получите позже, если захотите изучать программирование и компьютерные науки глубже.
Буфер — это массив определенной длины, расположенный в памяти. Переполнение буфера (buffer overflow) возникает, если мы пытаемся записать в него больше данных, чем предусмотрено размером этого массива. С помощью переполнения буфера злоумышленник может записать опасный код в память компьютера.



